Using RQ to Distribute Processing¶
Note
RQ does not currently work on Python 3. Emit should work with it (as it works with Python 2) when Python 3 support is ready.
RQ is a module that makes distributed processing easy. It’s similar to Celery, but simpler and only for Python and Redis. We’ll be using the same example as we did in the Celery example.
Installing¶
Emit can be installed pre-bundled with RQ by installing with the following extra:
pip install emit[rq-routing]
Setting up RQ¶
Create an app.py file for your RQ Router initializaition code to live in:
1 2 3 4 5 6 7 8 9 | 'simple rq app'
from redis import Redis
from emit.router.rq import RQRouter
import logging
router = RQRouter(redis_connection=Redis(), node_modules=['tasks'])
logging.basicConfig(format='%(levelname)s:%(message)s', level=logging.DEBUG)
|
The RQRouter class only needs to know what Redis connection you want to use. The rest of the options are specified at the node level.
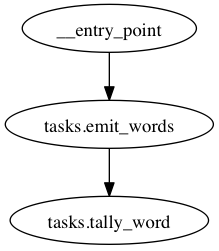
Next we’ll define (in tasks.py) a function to take a document and emit each word:
@router.node(('word',), entry_point=True)
def emit_words(msg):
for word in msg.document.strip().split(' '):
yield word
Without any arguments, RQ tasks will go to the ‘default’ queue. If you don’t want to mess with queues, this will just work.
If you want to set some attributes, however, you can:
@router.node(('word', 'count'), subscribe_to='tasks.emit_words', queue='words')
def tally_word(msg):
redis = Redis()
return msg.word, redis.zincrby('celery_emit_example', msg.word, 1)
Enqueued functions for this node will be put on the “words” node. You’ll need to specify which nodes to listen to when running rqworker.
The available parameters:
| parameter | default | effect |
|---|---|---|
| queue | 'default' | specify a queue to route to. |
| connection | supplied connection | a different connection - be careful with this, as you’ll need to specify the connection string on the worker |
| timeout | None | timeout (in seconds) of a task |
| result_ttl | 500 | TTL (in seconds) of results |
Running the Graph¶
We just need to start the RQ worker:
rqworker default words
And enter the following on the command line to start something fun processing (if you’d like, the relevant code is in examples/rq/kickoff.py in the project directory, start it and get a prompt with ipython -i kickoff.py):
from app import router
import random
words = 'the rain in spain falls mainly on the plain'.split(' ')
router(document=' '.join(random.choice(words) for i in range(50)))
And you should see the rqworker window quickly scrolling by with updated totals. Run the command a couple more times, if you like, and you’ll see the totals keep going up.
Performance¶
Because of the way RQ forks tasks, the graph is rebuilt for every task. To speed up this process, do it once on worker initialization. You can use this snippet (adapted from the RQ worker documentation)
#!/usr/bin/env python
import sys
import rq
# Preload libraries
from app import router
router.resolve_node_modules()
# Provide queue names to listen to as arguments to this script,
# similar to rqworker
with rq.Connection():
qs = map(rq.Queue, sys.argv[1:]) or [rq.Queue()]
w = rq.Worker(qs)
w.work()